
Dans cet article, nous allons explorer différentes techniques d'optimisation de jobs PySpark en nous concentrant principalement sur l’optimisation du code. Nous pourrons voir dans un prochain article les autres techniques d’optimisation des jobs PySpark (configuration des paramètres, utilisation de Spark UI).
Spark est un framework open source qui permet de traiter de grandes quantités de données grâce au calcul distribué. Il est principalement utilisé pour les jobs de traitement de données tels que les analyses de données massives, les traitements de flux de données en temps réel et les travaux d'apprentissage automatique.
Lorsque nous travaillons avec des grandes quantités de données sur Spark, il est important de s'assurer que notre code est optimisé afin d'améliorer les performances, notamment le temps d'exécution. Nous allons donc examiner quelques techniques d’optimisation.
1. Utilisation de fonctions natives de PySpark
Lors de l'écriture de jobs PySpark, il est important d’utiliser les fonctions natives de PySpark plutôt que de créer des fonctions personnalisées appelés UDF (User-Defined Function). Les fonctions natives de PySpark sont optimisées pour traiter les données distribuées à grande échelle et sont plus rapides que les fonctions personnalisées.
Exemple avant optimisation :
Exemple après optimisation :
Dans l'exemple avant l'optimisation, nous avons créé une fonction personnalisée square et l'avons transformée en une UDF que nous avons appliqué à la colonne col1 de notre DataFrame. Cependant, dans l'exemple après l'optimisation, nous avons utilisé directement la fonction native ** de PySpark pour calculer le carré de la colonne col1. Cela permet de garder des performances optimales car les fonctions de PySpark sont optimisées pour fonctionner sur des données distribuées.
Les UDF ne bénéficient pas de ces optimisations et seront plus lents, surtout pour les grands ensembles de données. De plus, PySpark propose souvent des fonctions déjà intégrées pour effectuer les opérations courantes de transformation et de manipulation de données. C’est pourquoi, avant d'utiliser une fonction UDF dans PySpark, il est important de vérifier dans la documentation de PySpark. Vous pouvez trouver plus d'informations sur les fonctions natives de PySpark dans la documentation officielle ici .
2. Utilisation de la fonction broadcast pour améliorer les performances des jointures
Lorsque nous effectuons des jointures entre des tables de tailles différentes, Spark doit transférer les données de la plus petite table à chaque nœud qui traite la jointure. Cela peut être très coûteux en termes de temps de traitement et de ressources. C'est là qu'intervient la fonction broadcast ! Cette fonction permet de stocker la table la plus petite en mémoire sur chaque nœud. Cela permet d'éviter le transfert de données coûteux tout en améliorant les performances de la jointure.
Exemple avant optimisation :
Exemple après optimisation :
Dans l'exemple avant l'optimisation, nous avons effectué une jointure entre les DataFrames df1 et df2 sans utiliser la fonction broadcast. Cela signifie que Spark a dû transférer la table df2 à chaque nœud qui traite la jointure. Cela peut s’avérer coûteux en termes de temps de traitement et de ressources. Cependant, dans l'exemple après l'optimisation, nous avons utilisé la fonction broadcast pour stocker la table df2 en mémoire sur chaque nœud. Cela évite le transfert de données coûteux et va considérablement améliorer les performances de la jointure.
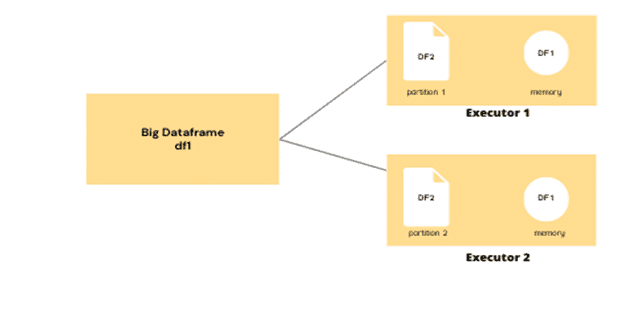
3. Utilisation de la fonction cache() dans PySpark
La fonction cache est utile pour améliorer les performances de PySpark dans les situations où nous avons besoin d'effectuer plusieurs opérations sur un même DataFrame.
Lorsque nous travaillons avec des données volumineuses, PySpark doit lire les données à chaque opération. Cela peut prendre beaucoup de temps si les données sont volumineuses. La fonction cache permet de stocker le DataFrame en mémoire et de l'y conserver pour éviter de lire les données à chaque opération.
La fonction cache est particulièrement utile dans les situations suivantes :
Lorsque nous effectuons plusieurs opérations sur le même DataFrame, comme des opérations de groupe ou de jointure.
Lorsque les données sont volumineuses et qu'il est coûteux de les lire.
Lorsque les données ne changent pas fréquemment et que nous pouvons nous permettre de stocker le DataFrame en mémoire pendant un certain temps.
Cependant, il est important de noter que la fonction cache utilise de la mémoire pour stocker le DataFrame. Cela peut être un problème si le DataFrame est très volumineux et que la mémoire est limitée. Dans ce cas, nous devons être judicieux quant à l'utilisation de la fonction cache et nous assurer que nous ne stockons pas trop de données en mémoire.
Voici un exemple de code pour utiliser la fonction cache avec PySpark :
Dans cet exemple de code, nous avons utilisé la fonction cache pour stocker le DataFrame en mémoire après l'avoir lu à partir du fichier CSV. Nous avons ensuite calculé la somme des ventes par année et le nombre de ventes pour chaque client en utilisant des opérations de groupe. Enfin, nous avons affiché les résultats en utilisant la méthode show. Après avoir terminé toutes les opérations, nous avons utilisé la méthode unpersist pour supprimer le cache du DataFrame et libérer la mémoire.
En utilisant la fonction cache, nous avons évité de lire les données à partir du fichier CSV à chaque opération sur le DataFrame. Cela a considérablement amélioré les performances de PySpark.
4. Partitionner correctement les données avec PySpark
Lors de l'analyse de données volumineuses avec PySpark, il est fréquent de rencontrer des DataFrames déséquilibré. Ce sont des DataFrames ayant un nombre disproportionné de lignes où les observations sont inégalement réparties entre les différentes partitions de données. Certaines partitions sont surchargées, tandis que d'autres sont sous-utilisées. Cela peut entraîner des performances médiocres lors de l'exécution d'opérations sur le DataFrame. En effet, les tâches ne sont pas réparties de manière égale entre les nœuds du cluster.
Nous pouvons vérifier le nombre de partition d’un dataframe spark avec le code suivant :
Pour répartir un DataFrame déséquilibré, nous pouvons utiliser la méthode repartition() de PySpark. La méthode repartition() redistribue les données du DataFrame en fonction du nombre de partitions spécifié. Plus précisément, elle répartit les données de manière uniforme sur toutes les partitions.
Nous pouvons également utiliser la méthode coalesce() pour réduire le nombre de partitions du DataFrame. La méthode coalesce() combine des partitions adjacentes pour réduire le nombre total de partitions du DataFrame. Cela peut être utile si nous avons trop de partitions et que nous voulons réduire le temps d'exécution des opérations.
Par exemple, si nous voulons réduire le nombre de partitions de notre DataFrame à 10, nous pouvons utiliser le code suivant :
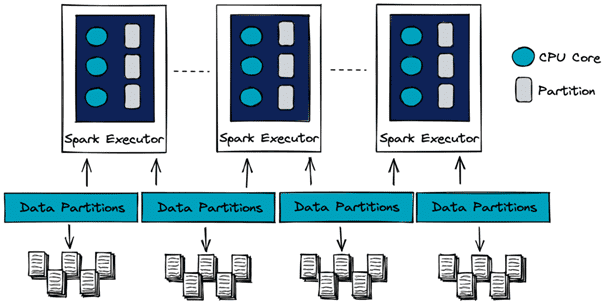
Le choix du nombre de partitions pour répartir un DataFrame dépend de plusieurs facteurs. Ces facteurs peuvent être la taille du DataFrame et surtout les ressources du cluster. La documentation Spark recommande d’utiliser 2 à 3 tâches par CPU. Le nombre de partitions à définir est donc de CPU x 3. En répartissant les données de manière uniforme sur toutes les partitions, nous avons pu améliorer les performances de notre DataFrame. Nous pouvons ainsi exécuter des opérations plus efficacement.
5. Utilisation du partitionnement de fenêtre pour effectuer des agrégations
Le partitionnement de fenêtre est une technique courante utilisée dans PySpark pour effectuer des agrégations sur des données distribuées. Cette technique consiste à partitionner les données en groupes selon une colonne donnée. Ensuite, cela demande d'effectuer des calculs sur chaque groupe. Le partitionnement de fenêtre est particulièrement utile lorsqu'il est nécessaire de calculer des agrégations sur des fenêtres de temps ou sur des groupes qui se chevauchent.
Exemple sans fenêtre :
Dans cet exemple, nous avons utilisé la méthode groupBy pour partitionner le DataFrame en groupes selon la colonne 'Region'. Ensuite, nous avons appliqué la fonction d'agrégation sum pour calculer la somme de la colonne Sales pour chaque groupe. Cela renvoie un nouveau DataFrame contenant la somme de Sales pour chaque valeur unique de Region.
Exemple avec window partition :
Dans cet exemple, nous avons utilisé la fonction Window pour partitionner le DataFrame en groupes selon la colonne Region. Ensuite, nous avons appliqué la fonction d'agrégation sum sur la colonne Sales en utilisant la méthode over. Ainsi, nous avons pu appliquer l'agrégation sur chaque groupe défini par la partition de fenêtre. Cela renvoie un nouveau DataFrame contenant la somme de Sales pour chaque groupe défini par la partition de fenêtre.
Lorsque nous utilisons la fonction window, PySpark effectue des opérations de groupe sur les données dans chaque partition du DataFrame, puis fusionne les résultats pour obtenir le résultat final. Cela est plus efficace que l'utilisation de la fonction groupBy pour les grandes tables, car PySpark peut effectuer les opérations de groupe sur chaque partition de manière parallèle et fusionner les résultats de manière efficace.
Conclusion
Dans cet article, nous avons exploré différentes techniques d'optimisation de jobs PySpark sur les DataFrames. Nous avons vu comment utiliser les fonctions natives de PySpark, les partitions optimales, la fonction cache pour stocker les résultats intermédiaires en mémoire. Nous avons également vu la fonction broadcast pour améliorer les performances des jointures.
En utilisant ces techniques, nous pouvons minimiser le temps de traitement et maximiser les performances de nos jobs PySpark sur les DataFrames. C'est crucial lors du traitement de grandes quantités de données distribuées.





