
Le C++ est un des langages les plus utilisés aujourd’hui en finances, notamment pour ses performances. Sa première normalisation par l’Organisation internationale de normalisation (ISO) a lieu en 1998. S’ensuit une simple version de correctifs de bugs en 2003. Ce n’est qu’avec la révision C++11, publié en Septembre 2011, que l’on va véritablement voir apparaître une vraie mise à jour avec de nouveaux outils de développement pour améliorer les performances et faciliter la vie du développeur. En outre, le C++11 introduit une nouvelle gestion de l’objet temporaire, dont l’impact sur les performances est souvent sous-estimé.
Limites du C++98/03
Dans quels cas retrouve-t-on des variables temporaires ? Voici deux exemples simples qui vont illustrer le sujet.
Figure 1: Utilisation d'une variable et d'une fonction qui retourne par valeur
Dans l’exemple ci-dessus, on a une fonction qui prend en paramètre le nom et prénom d’un client et retourne par valeur l’ID correspondant.
Quel est le problème avec cette implémentation ?
Lors de l’utilisation de la fonction retrieveCustomerId, on pourrait avoir en théorie deux copies : la première lors de l’appel au return de la fonction et la seconde lors de l’initialisation de la variable id (en pratique, la première copie est évitée avec les optimisations du compilateur).
Regardons un second exemple :
Figure 2: Utilisation d'un constructeur par copie
Dans cet exemple, on a une classe Basket qui contient un vector d’IDs d’objets.
Dans un premier temps, une première instance de la classe Basket myOriginalBasket est créée et on y ajoute des IDs. Ensuite, myNewBasket est instancié à partie de myOriginalBasket. Le constructeur par copie est appelé et tous les éléments du vector de myOriginalBasket sont copiés dans le vector de myNewBasket.
Dans ce cas de figure assez simpliste, nous avons créé un objet temporaire qui va être utilisé pour créer notre objet de travail par copie.
Dans les deux exemples ci-dessus, nous avons montré que l’utilisation d’objets temporaires pouvaient engendrer des opérations de copie supplémentaires. Pour nos exemples simples, cela ne pose pas de problèmes de performance, mais dans des applications critiques utilisant de grands nombres de données, cela peut vite devenir problématique.
C++11 : Reference sur rvalue &&
Avant d’aller plus loin, nous allons nous intéresser à la question : qu’est-ce qu’une rvalue ?
La notion de rvalue (« right hand value ») vient en complément de la notion de lvalue (« left hand value »).
Une lvalue désigne un élément nommé dont l’adresse mémoire peut être accédé via son nom. Une rvalue désigne une valeur non-nommé temporaire qui n’existe uniquement pendant l’évaluation d’une expression. Pour que cela soit plus clair, regardons l’exemple ci-dessous :
On a une variable « x » à qui on va assigner la valeur « 2+3 ».
« x » est une variable nommée à laquelle on peut accéder dans la suite du code, c’est donc une lvalue. Au contraire, « 2+3 » est temporaire et existe uniquement lors de l’opération d’initialisation, c’est donc une rvalue.
En pratique les lvalues sont situées à gauche de l’opérateur ‘=’, tandis que les rvalues sont à droite ; d’où leurs noms respectifs.
La déclaration d’une référence sur une lvalue se fait avec l’opérateur « & ». La déclaration d’une référence sur une rvalue se fait tout simplement avec l’opérateur « && ».
A quoi sert ce nouveau type de références ? Tout simplement, à lier une référence constante ou non à une valeur temporaire.
On arrive naturellement à la question : comment cela s’applique-t-il en pratique ?
Reprenons le premier exemple que nous avons vu.
Le problème relevé précédemment était que lors de l’utilisation de retrieveCustomerId dans le main, de possibles copies s’effectuaient lors de l’initialisation. D’après ce que nous venons de voir plus haut, nous pouvons réécrire différemment le code :
Figure 3: Utilisation d'une référence sur rvalue
En effet, retrieveCustomerId(‘’Doe’’,’’John’’) étant une rvalue, nous pouvons utiliser l’opérateur && afin de créer une référence sur celle-ci. Comme les références classiques, ici la string retournée par notre méthode ne va pas être détruite immédiatement et va être accessible via sa référence nommée id sans copie. De plus, comme les références classiques, les références de rvalues vont pouvoir être utilisées comme paramètres de fonctions ce qui va permettre de nombreuses applications.
Constructeur par déplacement et std::move
Une des applications majeures de la référence sur rvalue est la création de constructeurs par déplacement. Comme son nom l’indique, le but est de transférer les éléments d’un premier objet vers le second.
Reprenons le deuxième exemple avec le constructeur par copie et adaptons-le pas à pas afin d’appliquer ce nouveau concept. Tout d’abord, ajoutons à la classe Basket un constructeur par déplacement.
Figure 4: Premier essai d'écriture d'un constructeur par déplacement
Dans un premier temps essayons tout simplement d’utiliser une référence sur une rvalue vue précédemment.
Après exécution on obtient le résultat suivant :
Ce qui est exactement le même résultat que plus haut… Pour mieux comprendre il faut regarder le main.
Donc comme vous pouvez le constater, le paramètre utilisé pour le constructeur de myNewBasket n’a pas été modifié, d’où l’appel au constructeur par défaut.
On est maintenant face à une nouvelle problématique : comment faire en sorte d’appeler le constructeur par déplacement que nous venons d’écrire ?
Pour cela nous pouvons utiliser la fonction std::move, introduite avec le C++11. En effet, cette fonction prend en paramètre une donnée et va retourner une référence sur une rvalue.
Rectifions maintenant notre exemple en ajoutant les appels à la fonction move.
On voit bien que c’est le constructeur par déplacement qui est maintenant appelé.
Notez que nous avons également utilisé la fonction std::move afin d’initialiser l’attribut objectsIds_. Ceci est possible car la sémantique de déplacement a été ajoutée à la STL avec la révision de 2011.
Comparaison des performances
Nous avons vu que le standard C++11 a introduit une nouvelle manière de gérer les objets temporaires tout en évitant les copies inutiles. Mais en pratique, observons-nous une vraie différence ?
Reprenons notre classe Basket et on compare les performances du constructeur par copie et du constructeur par déplacement que nous avons écrit. Pour cela, on va créer un objet Basket, contenant un vector de 1000000 éléments. Puis pour chacun des cas, nous imprimons la durée de traitement en secondes.
On constate que le constructeur par déplacement est 1000 fois plus rapide que le constructeur par copie.
Cas pratique : définition d’une classe string personnalisée
Nous allons désormais appliquer ce qu’on a vu précédemment dans la définition d’une classe String personnalisée qu’on va appeler MyString.
Commençons par écrire les grandes lignes :
Nous avons donc créé une classe MyString, ayant comme attribut :
buffer_: une chaine de caractères qui va contenir notre string
size_ : un size_t qui va contenir la taille de notre string
Nous avons également ajouté un constructeur qui va initialiser notre buffer avec une chaîne de caractères et une taille en entrées. N’oubliez pas lors de l’allocation mémoire d’ajouter +1 pour prendre en compte le caractère de fin de chaîne. De plus, nous ajoutons le destructeur pour désallouer notre buffer lors de la destruction de nos instances. Notez que nous désallouons un tableau, il ne faut donc pas oublier [].
Enfin nous définissions une méthode print pour afficher notre buffer et ainsi que sa taille.
Exécutons le code et observons la sortie :

A première vue, on a un message d’erreur qui nous informe d’un pointeur invalide. Regardons de plus près ce qu’il se passe.
Dans un premier temps on construit nos deux instances de MyString s et s2 avec le constructeur que nous avons défini. On peut voir sur la sortie la construction de ces deux strings ainsi que les adresses mémoires des deux chaînes de caractères. Ensuite, nous affectons à s2 à s. En affichant avec la méthode print nos deux objets, on constate que l’affectation semble avoir bien fonctionné puisque nos buffers ont la même valeur et la même taille.
Néanmoins, on peut voir lors de la destruction de nos deux objets que les deux pointeurs pointent en fait vers la même adresse. En effet, le problème est que nous avons utilisé l’opérateur d’affectation mais nous ne l’avons pas explicitement défini. Dans ce cas, le compilateur va créer un opérateur d’affectation par défaut qui ne va pas copier le contenu d’une chaîne de caractères dans une autre mais copier les pointeurs.
De manière générale, pour éviter ce genre de problèmes, la bonne pratique est de toujours définir explicitement l’opérateur d’affectation et le constructeur par copie. S’ils ne sont pas utilisés ou on veut y interdire l’accès, on pourra toujours les mettre en private dans l’interface de la classe.
Ajoutons donc notre constructeur par copie et notre opérateur d’affectation à notre classe MyString :
Modifions également notre main pour illustrer ces nouvelles fonctionnalités :
On obtient après exécution :
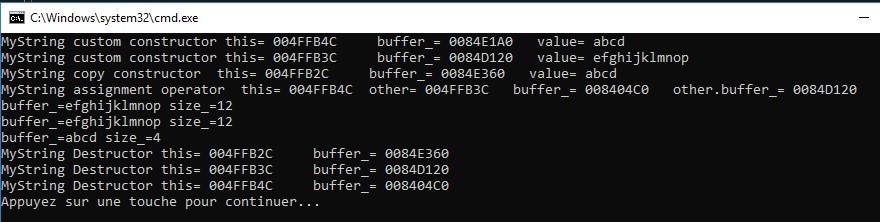
On remarque que cette fois, les pointeurs buffer_ sont tous différents pour nos 3 instances de MyString.
Ajoutons désormais l’opérateur +
On modifie également le main et on adapte les affichages puis on exécute.
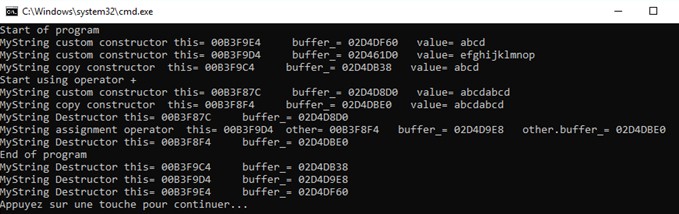
On constate que lors de l’utilisation de notre opérateur + :
L’appel à notre custom constructeur qui correspond à notre instanciation de newString : adresse de buffer_ = 02D4D8D0
L’appel à un constructeur par copie : newString est copié dans un objet temporaire lors du return newString : adresse de buffer_ = 02D4DBE0
newString est désalloué puisqu’on sort du corps de la méthode : adresse de buffer_ = 02D4D8D0
L’objet temporaire précédemment créé est utilisé lors de l’affectation de s2 : adresse du buffer_ temporaire utilisé = 02D4DBE0
L’objet temporaire est désalloué : adresse de buffer_ = 02D4DBE0
Définissons désormais le constructeur par déplacement vue plus haut :
Nous avons également défini ce qu’on appelle l’opérateur d’assignation de déplacement, qui prend en paramètre une référence sur rvalue. Il suit la même logique que le constructeur de déplacement, son but étant de déplacer les éléments d’un objet vers un autre déjà créé. Ainsi, il ne faut pas oublier de désallouer la donnée que l’on souhaite remplacer.
Exécutons désormais notre main, qu’on a laissé inchangé.
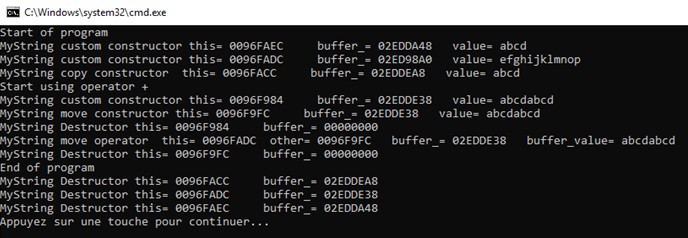
On constate que le constructeur par copie et l’opérateur de copie ont été automatiquement remplacés par leurs équivalences en déplacement, la valeur ‘s + s3’ étant une rvalue. Comme on peut le voir dans les implémentations au-dessus, à la comparaison du constructeur par copie et de l’opérateur d’affectation par copie, on se contente ici uniquement de déplacer les pointeurs d’un objet à un autre sans faire appel à la fonction memcpy.
Cela est également confirmé par les traces qu’on affiche :
L’appel à notre custom constructeur qui correspond à notre instanciation de newString : adresse de buffer_ = 02EDDE38
L’appel à un constructeur par déplacement : newString est transféré sans copie dans un objet temporaire lors du return newString : adresse de buffer_ = 02EDDE38
newString est désalloué puisqu’on sort du corps de la méthode : adresse de buffer_ = 00000000
L’objet temporaire précédemment créé est utilisé lors de l’affectation par déplacement de s2 : adresse du buffer_ temporaire utilisé = 02EDDE38
L’objet temporaire est désalloué : adresse de buffer_ = 00000000
Par conséquent en implémentant le constructeur par déplacement et l’opérateur d’affectation par déplacement, on a pu dans cet exemple éviter deux copies inutiles de notre buffer. Dans notre exemple, les buffers étaient relativement peu couteux en mémoire et notre programme très simple. Cependant on peut facilement imaginer le grand nombre de copies inutiles si on avait travaillé avec des chaînes de caractères beaucoup plus grandes et beaucoup plus d’opérations.
Conclusion
Tout au long de cette article, nous avons pu découvrir une nouvelle méthode plus performante de gestion des objets temporaires au travers des références sur rvalues. Par exemple, nous avons pu voir l’utilisation du constructeur par déplacement ainsi que l’opérateur de déplacement =. Notez que ceux-ci sont également implémentés dans tous les containers de la STL.
Cependant, cela ne correspond qu’à une toute petite partie de la révision C++11. En effet, d’autres améliorations importantes ont été apportées par cette révision tels que les smart pointers ou encore le support des threads.





